从Web上获取数据
很多时候对于我们需要的数据,我们没有足够的能力去自己进行寻找、统计等工作。这个时候,我们就需要去求助互联网。那么怎么去从Web上获取我们想要的数据呢?那就接着往下看。
分析网页结构
这里我们以豆瓣电影TOP250网页为例。
打开豆瓣电影TOP250首页,观察网页信息,可以看到,总共10页,每页25部电影推荐
.png)
点击下一页,可以发现,网页的URL发生了变化。 start后面的数值变为25,由此我们可知每翻一页start的值就加25
.png)
创建爬虫主体
从PowerBI上获取Web数据
.png)
.png)
由于网页上没有明确的表单,PowerBI并未将识别的数据划分成我们想要的表单。点击左下角--使用示例添加表
.png)
设置自己需要的列,在表格内输入对应的内容。PowerBI若识别出输入内容,则会出现下拉框,可在下拉框中补全你所想要输入的文字。图中颜色加深的文字内容是手动输入,PowerBI会自动识别所输入的文字并进行匹配,若识别内容有遗漏,则可多输入几个数据加强匹配。点击确定,选择自定义表,转换数据。
.png)
.png)
接下来就是要去实现让PowerBI自动去获取后面几个网页的数据。更改查询名称为电影TOP250,工具栏管理参数--新建参数,参数类型设置为文本,当前值为0,确定。
.png)
选择电影TOP250查询,点击右侧应用的步骤中源右侧的设置按钮。这里我们将网页的URL分成三个部分,在中间将需要变化的数值0用参数页码代替,点击确定。
.png)
选中电影TOP250,右键,创建函数,命名为电影获取
.png)

接下来就是构建输入参数里的页码列表了。工具栏--新建源--空查询,这里调用List.number函数,第一个参数表示给定初值,第二个参数表示计数,第三个参数表示增量值。List不能直接应用,右键将其转换到表,转换后的表为数值类型,注意将其变更为文本。

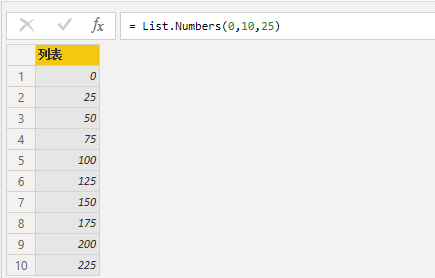
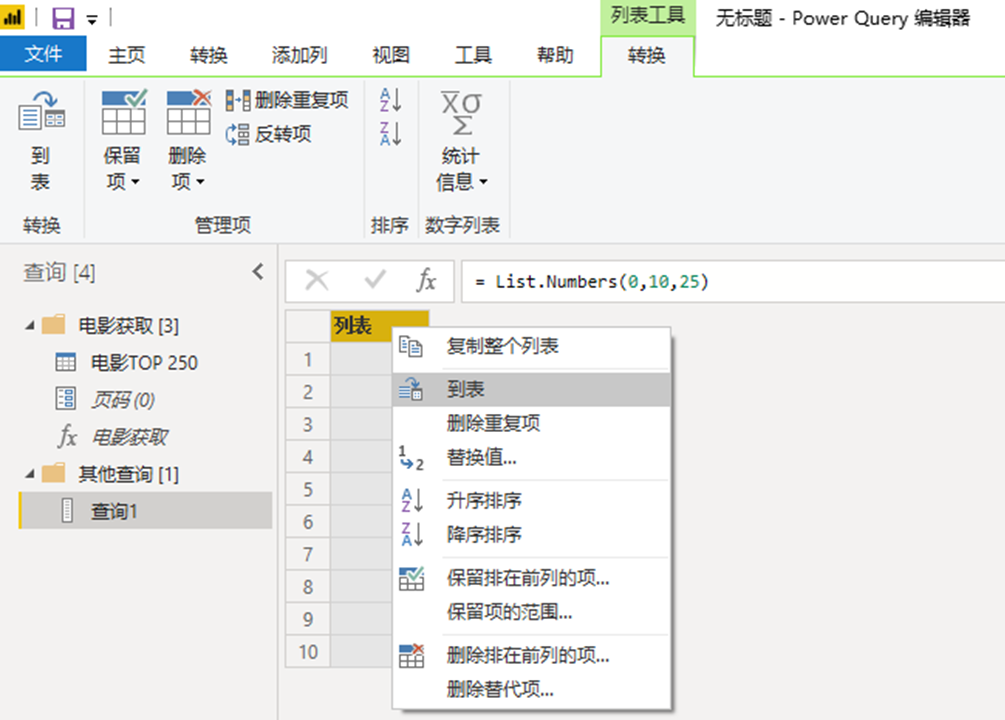
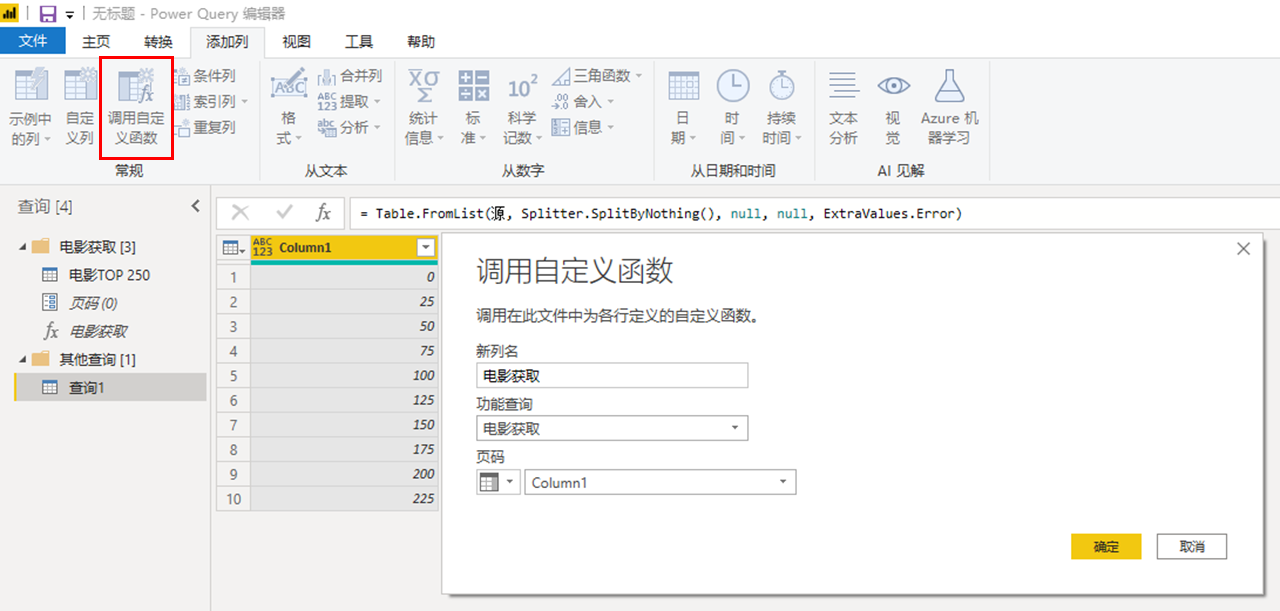
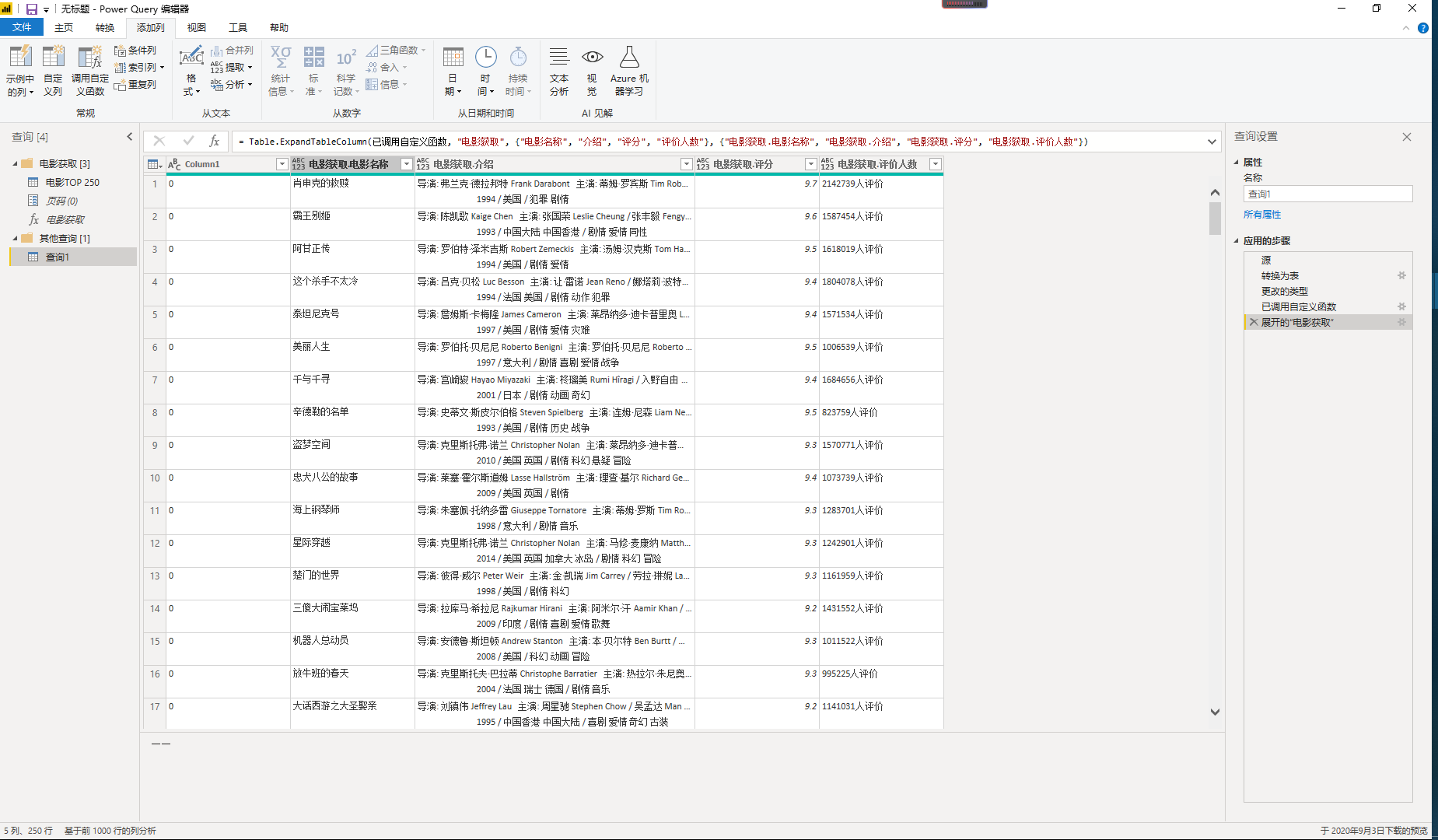
最后,我们将页码表引入到函数中。选择新建的查询1,菜单栏--添加列,调用电影获取函数,页码对应Column1。最后展开自定义列,web数据爬取成功。
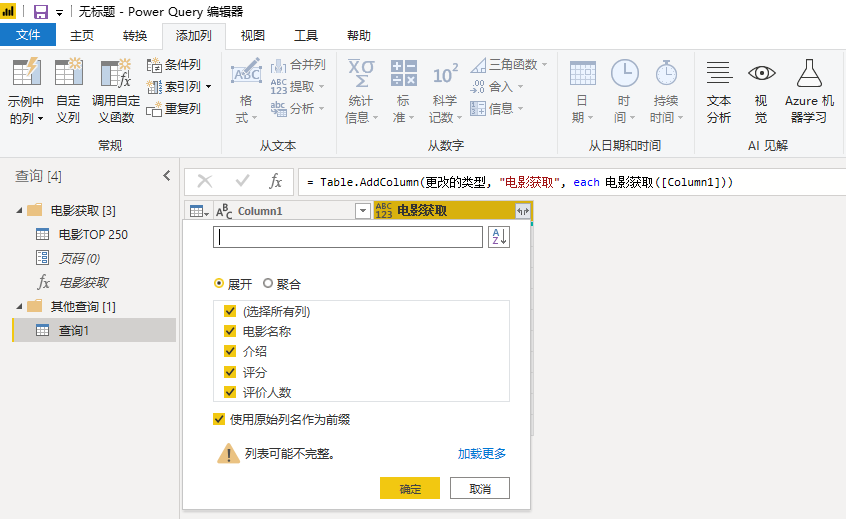
- 数据来源豆瓣电影TOP250